
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- relational database
- 영속성전이
- 분할상환분석
- DB
- n+1문제
- commit
- 즉시로딩
- MappedSuperclass
- Amortized Analysis
- Flush
- Spring
- 엔티티 매핑
- fetch join
- DiscriminatorColumn
- Embeddable
- ROLLBACK
- 고아객체
- 지연로딩
- 값타입
- 플러시
- Algorithm
- 관계형 데이터베이스
- 영속성 컨텍스트
- 페치조인
- Spring Data JPA
- 정렬
- JPA
- DiscriminatorValue
- relational DB
- 순수jpa
Archives
- Today
- Total
Jun's note
[JPA] JPA 동작 과정과 장점 본문
728x90
JPA에 대해 자세히 알기전에 ORM, JDBC와의 관계를 정확히 알고 넘어가야 그 다음 내용도 이해하기 쉽다.
이전 포스팅에 JPA의 정의와 개념, ORM, JDBC에 대해 정리했다.
지금부터는 JPA에 대한 자세한 내용을 정리한다.
1. JPA 동작 과정
- JPA는 애플리케이션과 JDBC 사이에서 동작

- JPA가 DB에 값을 저장할때
- JPA가 DB로부터 값을 조회할때
2. JPA 장점
1. SQL 중심적인 개발 -> '객체' 중심으로 개발
- Java에서 객체 중심으로 개발하고 이를 DB에 객체 형태로 저장하고 싶은데, JPA를 사용하면 이 문제가 해결된다.
2. 생산성
- CRUD가 간단하게 구현된다.
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName(“변경할 이름”)
- 삭제: jpa.remove(member)
3. 유지보수
- 필드 변경시 JPA로 필드만 추가하면 되고, SQL은 JPA가 알아서 처리한다.
- 쉽게 말하면, 회원을 수정할 경우 member.setName(“변경할 이름”) 를 사용하여 수정하고 따로 SQL문은 고려하지 않는다. (왜? JPA가 알아서 SQL문을 짜서 DB에 넣음)
4. 패러다임의 불일치 해결
- 객체를 DB에 저장할 때 불일치가 생긴다. 왜냐하면 객체는 상속 기능이 있지만, 테이블에는 상속기능이 없다.
- 위 문제를 아래 그림과 같이 해결한다. (테이블에서 상속과 비슷한 '슈퍼타입 서브타입 관계'를 사용하여 설계)
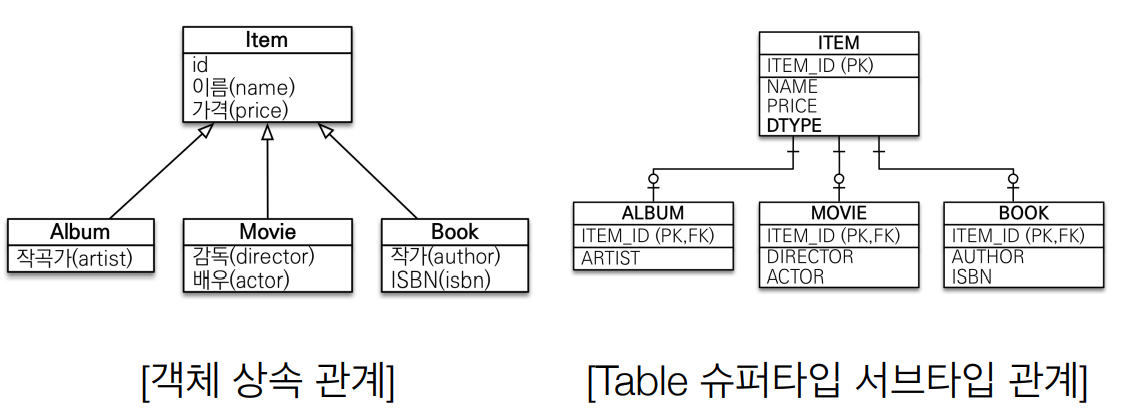
- 객체모델을 아래 코드와 같이 명시해준다.
abstract class Item {
Long id;
String name;
int price;
}
class Album extends Item {
String artist;
}
class Movie extends Item {
String director;
String actor;
}
class Book extends Item {
String author;
String isbn;
}- 개발자는 자바 컬렉션에 저장하듯이 JPA에게 객체를 저장하면 된다.
- 예를 들어, 앨범을 저장하고 싶다면
- jpa.persist(album); 이 한줄로 저장하면 끝이다.
- 그러면 JPA가 스스로 상속관계임을 알고, INSERT INTO ITEM ... , INSERT INTO ALBUM ... 이 SQL문을 수행한다.
- 패러다임의 불일치는 '상속' 이외에도, '연관관계' ' 객체 그래프 탐색' '비교하기' 도 있다.
5. 성능
1) 1차 캐시와 동일성 보장
- 같은 트랜잭션 안에서는 같은 엔티티를 반환
- SQL 한번만 수행
String memberName = "Kim"
Member m1 = jpa.find(Member.class, memberName); // SQL
Member m2 = jpa.find(Member.class, memberName); // 1차 캐시
print(m1 == m2) // true
//첫번째 조회할때에는 SQL에서 조회
//두번째 조회할때에는 1차 캐시에서 조회 (값이 1차 캐시에 저장되어있기 때문에 SQL을 거치지않음)
2) 트랜잭션을 지원하는 쓰기지연
- 트랜잭션을 마지막에 커밋하는 순간, 쓰기 지연 저장소에 모아뒀던 SQL문을 모두 수행한다. (SQL 한번 수행)
transaction.begin();
em.persist(MemberA);
em.persist(MemberB);
em.persist(MemberC);
transaction.commit(); // sql문 한번 수행
3) 지연로딩과 즉시로딩
- 지연로딩: 모아뒀다 한번에 하나의 sql문으로 수행 (실무에서 이걸로 써야함)
- 즉시로딩: 그때그때 sql문 수행
참고
강의 : www.inflearn.com/course/ORM-JPA-Basic
서적 : <자바 ORM 표준 JPA프로그래밍> 김영한
'Programming > JPA' 카테고리의 다른 글
| [JPA] 상속관계매핑, @MappedSuperclass (0) | 2022.01.14 |
|---|---|
| [JPA] 다양한 연관관계 매핑 (다대일, 일대다, 일대일, 다대다) (0) | 2022.01.13 |
| [JPA] 엔티티(Entity), 연관관계 매핑 (0) | 2022.01.13 |
| [JPA] 영속성 컨텍스트 개념, 이점 (0) | 2022.01.13 |
| [JPA] JPA, ORM, Spring Data JPA 란? (0) | 2022.01.13 |
'Programming/JPA' Related Articles
more




Comments